
Homework 10: Large Language Models
In this homework, you will use the OpenAI API to understand the current state-of-the-art in large language models that have been trained using deep neural networks. We’ll get you started by introducing you to the OpenAI playground and introducing the notion of prompt design. Then we’ll show how to fine-tune the models to perform specific tasks.
Getting Started with the OpenAI API
You should sign up for the OpenAI API, which lets you use GPT-3 a large, neural language model like the ones that we learned about in lecture.
The OpenAI API is a paid service. OpenAI will give you $18 in credit when you first create your account. For this assignment, the cost should be less than that. For the first part of the assignment, we’ll get warmed up by playing with the OpenAI API via its interactive Playground website. Later we’ll see how to integrate it directly into our code.
First, let’s learn some basic terminology:
- Prompt - the input to the model
- Completion - what the model outputs
Let’s try it out. Try pasting this prompt into the playground, pressing the “Generate” button, and see what it says:
My favorite professor at the University of Pennsylvania is
Now try changing the prompt to
My favorite professor at the University of Pennsylvania is Chris Callison-
and generating again. Now save its output for the end of the semester for your course reviews. (Just kidding). Here’s an example of what it generated when I ran it.
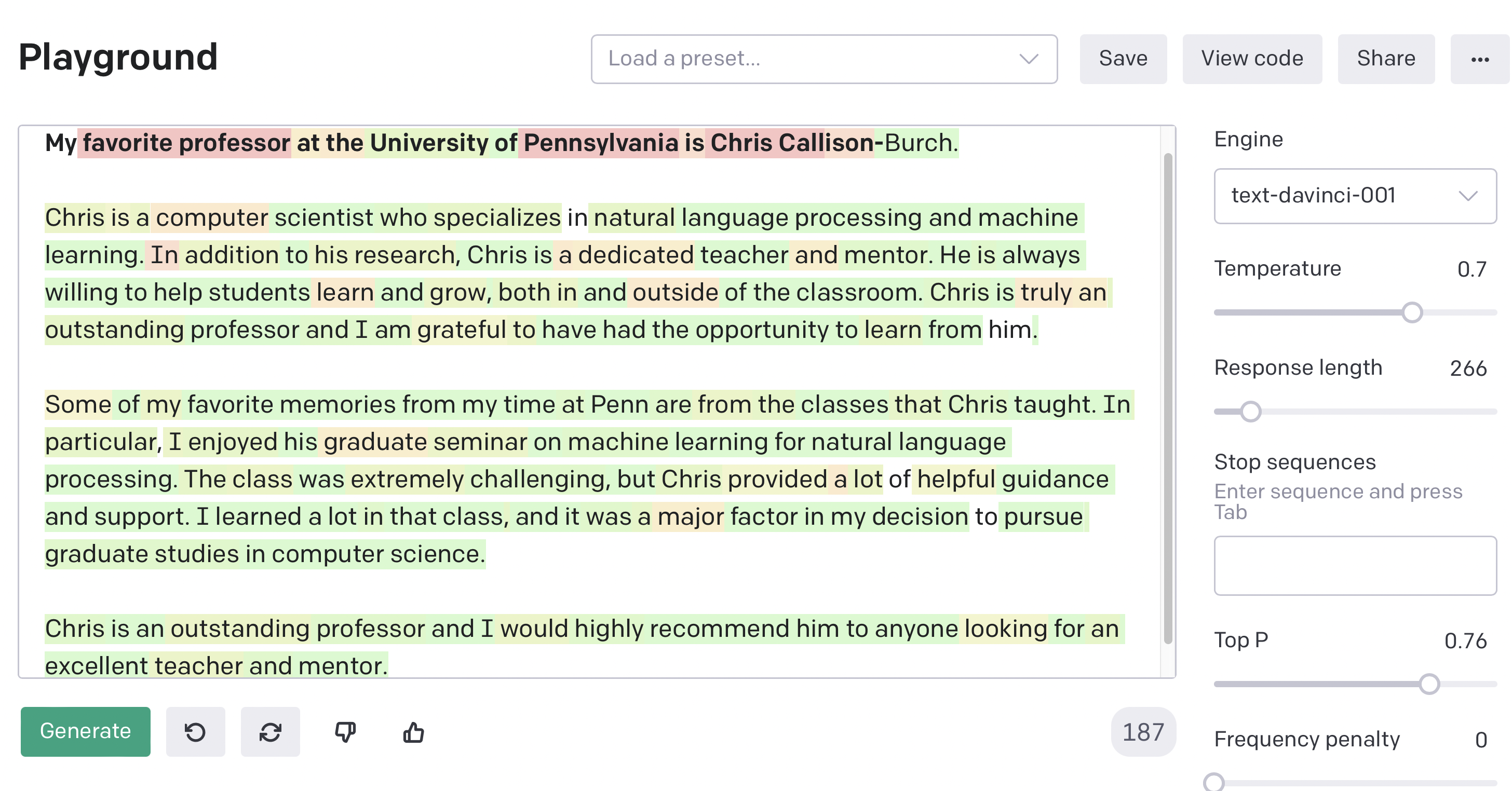
Here’s another impressive example of what GPT-3 knows about the field of NLP.
{kind=link}
There are several controls on the right hand side of the playground. These are
- Engine - GPT-3 comes in 4 different sized models. As the model sizes increase, so does their quality and their cost. They go in alphabetical order from smallest to largest.
- Ada - smallest, least costly model.
- Babbage
- Curie
- Davinci - highest quality and highest cost model.
- Response length - what’s the maximum length (in tokens) that the model will output?
- Stop sequence - you can specify what tokens should cause the model to stop generating. You can use the newline character, or any special sequence that you designate.
- Show probabilities - allows you to highlight the tokens giving them different colors for how probable the models think they are.
- Temperature and Top P sampling - control how the model samples tokens from its distribution.
- Setting Temperature to 0 will cause the model to produce the highest probability output. Setting it closer to 1 will increase its propensity to create more diverse output.
- Top P sampling controls the nucleus sampling, where the model samples from only the top of the distribution.
- Frequency Penalty and Presence Penalty - two parameters that help to limit how much repetition there is in the model’s output.
Prompt design
In addition to writing awesome reviews of your professors, you can design prompts to get GPT-3 to do all sorts of surprising things. For instance, GPT-3 can perform few-shot learning. Given a few examples of a task, it can learn a pattern very quickly and then be used for classification tasks. It often helps to tell the model what you want it to do.
Here’s an example from the paper that introduced GPT-3. It shows a few-show learning example for correcting grammatically incorrect English sentences.
Poor English input: I eated the purple berries.
Good English output: I ate the purple berries.
Poor English input: Thank you for picking me as your designer. I’d appreciate it.
Good English output: Thank you for choosing me as your designer. I appreciate it.
Poor English input: The mentioned changes have done. or I did the alteration that you requested. or I changed things you wanted and did the modifications.
Good English output: The requested changes have been made. or I made the alteration that you requested. or I changed things you wanted and made the modifications.
Poor English input: I’d be more than happy to work with you in another project.
It will then generate “Good English output: I would be happy to work with you on another project.”. Input “Poor English input: Please provide me with a short brief of the design you’re looking for and that’d be nice if you could share some examples or project you did before.” it will generate “Good English output: Please provide me with a brief description of the design you are looking for, and it would be helpful if you could share some examples or projects you have done before.”.
You can use the playground to create code based on a prompt that you can then use in your Python projects. Click on the “View Code” button, and you’ll get some code that you can convert into a Python function that takes a direction as input and returns the reverse direction. For example:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create(
model="text-davinci-002",
prompt="Poor English input: I eated the purple berries.\nGood English output: I ate the purple berries.\nPoor English input: Thank you for picking me as your designer. I’d appreciate it.\nGood English output: Thank you for choosing me as your designer. I appreciate it.\nPoor English input: The mentioned changes have done. or I did the alteration that you requested. or I changed things you wanted and did the modifications.\nGood English output: The requested changes have been made. or I made the alteration that you requested. or I changed things you wanted and made the modifications.\nPoor English input: I’d be more than happy to work with you in another project.\n",
temperature=0.7,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
In addition to few shot learning, GPT-3 and other large language models do a pretty remarkable job in “zero-shot” scenarios. You can give them instructions in natural language and they will frequently produce remarkably good output.
If you input the prompt
Correct this English text: Today I have went to the store to to buys some many bottle of water.
It outputs
Today I went to the store to buy some bottles of water.
Fine-Tuning
Next, we’ll take a look at how to fine-tune the OpenAI models to perform a specific task. You can use few-shot learning when you have a few dozen training examples, and you can use fine-tuning when you have several hundred examples. When we have a few hundred training examples, then it’s not possible to fit them all into a prompt, since GPT-3 has a limit of 2048 tokens in the prompt.
For your homework, you’ll fine-tune GPT-3 to generate biographies from tables of information about a person. For instance, given
notable_type: mountaineer
name: Olev Vilhelmson
gender: male
nationality: Latvian
birth_date: 07 November 1876
birth_place: Jelgava, Latvia
death_date: 21 February 1952
death_place: Geneva, Switzerland
death_cause: pneumonia
resting_place: La Chaux-de-Fonds Cemetery
start_age: 12
notable_ascents: First ascent of Mt. Kebnekaise in 1894, Youngest person to climb All peaks higher than 4,000 meter 1895
final_ascent: Highest Peak in Sweden and Scandinavia
partnerships: Gustaf Bergmann, Björn Dunker
mother: Emilia Vilhelmina Bartlett
father: Gustav Vilhelmson
partner: Anna Hulthorst
children: Vilhelmina Bergman-Malmstroem, Elsa Bergman-Malmstroem
Your model will generate something like:
Olev Vilhelmson (7 November, 1876 - 21 February, 1952) was a Latvia. He was born in Jelgava, Latvia, His start age is 12. He had partnerships with Gustaf Bergmann and with Bjorn Dunker. His father was Gustav Vilhelmson and his mother was Emilia Vilhelmina Bartlett. Vilhelmson’s first ascent was Mt. Kebnekaise in 1894. He was also the youngest person to climb all peaks higher than 4,000 meters in 1895. He died of pneumonia on February 21, 1952 in Geneva, Switzerland. He was buried in the cemetery of Chaux-de-Fonds. He was married to Anna Hulthorst and had two children Vilhelmina Bergman-Malmstroem, Elsa Bergman-Malmstroem.
You’ll also fine tune a model to do the reverse direction. Given a Wikipedia style biography, your model will extract a table of information describing the person.
What to submit
Please submit your completed Colab Notebook to Gradescope. The notebook has several functions marked TODO that you will need to complete.
Remember to make a copy of the notebook into your own Drive by choosing “Save a Copy in Drive” from Colab’s “File” menu.
Recommended readings
| OpenAI API Documentation |
| Language Models are Few-Shot Learners - Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei. NeurIPs 2020. |
| Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing - Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig. arXiv 2022. |
| Multitask Prompted Training Enables Zero-Shot Task Generalization - Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Tali Bers, Stella Biderman, Leo Gao, Thomas Wolf, Alexander M. Rush. arXiv 2022. |
| Truth, Lies, and Automation How Language Models Could Change Disinformation - Ben Buchanan, Andrew Lohn, Micah Musser, Katerina Sedova. arXiv 2021. |