
Robot Exercise 3: R2-D2 Battle [75 points]
Preface
The First Galactic Empire dispatched Darth Vader and their evil robot R2-Q5 to destroy the base of Rebel Alliance. Our brave R2-D2s will battle with the dark robots and reclaim the land of Rebellion. May the force be with you, R2-D2s.
Instructions
In this assignment, you will combine your knowledge of reinforcement learning and the adversarial search game tree to teach the R2-D2s how to play optimally in a laser-shooting game.
In this game, there will be two robots against each other. One team will be using a D2 robot, and the other team will be using a Q5 robot. The goal of the game is to have your own team “win” by giving more shots to the other team and prevent being shot by the other team at the other time.
A skeleton file r2d2_hw3.py containing empty definitions for each question has been provided. Some helper functions and functions required for GUI are also provided. Please do not change any of that. Since portions of this assignment will be graded automatically, none of the names or function signatures in this file should be modified. However, you are free to introduce additional variables or functions if needed.
You are strongly encouraged to follow the Python style guidelines set forth in PEP 8, which was written in part by the creator of Python. However, your code will not be graded for style.
Once you have completed the assignment, you should submit your file on Gradescope.
0. Explanation of the Game
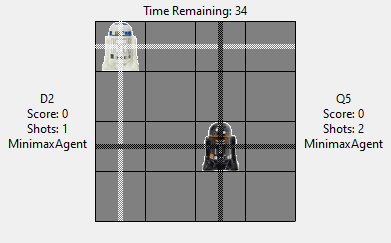
The action space of this game is defined as a row times cols sized rectangle board. Where one robot occupies a single cell on the board at any given time of the game.
The games starts with two droids at two different location of the board. Both droids start with the same number of shots that they can perform. Both droids need to perform one of actions available to them at each round of the game simultaneously. Droids can either move up, down, left or right, if they are not blocked by the walls on the direction they are moving towards, or they can choose to shoot, if they have shots remaining.
Once received both actions decided by two droids, the actions will be performed in a way such that they will first move (if they decide to move) and then shoot (if they decide to shoot).
If both droids decide to move and not blocked by the wall, but they are either
- moving heading each other (they want to move onto the other one’s location), or
- moving onto the same location
Then the action does not take actual effect (although it is a “valid” move to them). Notice that if one droid decides to step onto the other one’s previous location, but at the same time the other droid decide to move away (not heading each other), then the action is valid and will be performed.
If a droid can and decide to shoot, a laser beam will be emitted from its location to all four sides all the way to the walls (i.e. occupies the entire row and column it’s on, see the image). If the other droid is on the path of the laser (after it moved, if it decided to) of the laser beam, then the other droid is count as hit, and the shooting droid gains a point. Notice that both droids can shoot at the same time, and if they are both hit at the same time, neither hit is counted.
The game ends if both droids run out of shots, or the game has ran for 50 rounds, whichever comes first. When the game ends, the side that has the more points wins, otherwise it’s a draw.
1. Create the Droid Instance [20 points]
- [2 points] You will be given the size of the board, along with the location (which is a
(int, int)tuple) your droid is located at in the beginning of the game, and the number of shots the droid has. These parameters will be passed to the constructor of ourR2Droidclass.
class R2Droid:
def __init__(self, rows: int, cols: int, location: Location, shots: int):
Your droid should have two public fields called location and shots which represents the current location and number of remaining shots of the droid respectively.
>>> droid = R2Droid(4, 4, (0, 0), 5)
>>> droid.location
(0, 0)
>>> droid.shots
5
- [3 points]
copy(self)should return a copy of the droid instance, changes to which should not affect the original droid.
>>> droid = R2Droid(4, 4, (0, 0), 5)
>>> droid_copy = droid.copy()
>>> droid_copy.location = (1, 1)
>>> droid.location
(0, 0)
>>> droid_copy.location
(1, 1)
- [5 points]
move_location(self, move: Action)should take in anActionnamedmove, whereActionis an enum defined in the python file, and perform the action only if it is a movement action (i.e. notSHOOT). If themoveis not valid, do not change the location of the droid.
>>> droid = R2Droid(4, 4, (0, 0), 5)
>>> droid.move_location(Action.MOVE_DOWN)
>>> droid.location
(1, 0)
>>> droid.move_location(Action.MOVE_RIGHT)
>>> droid.location
(1, 1)
>>> droid = R2Droid(4, 4, (0, 0), 5)
>>> droid.move_location(Action.MOVE_LEFT)
>>> droid.location
(0, 0)
- [5 points]
shoot(self, other: 'R2Droid', move: Action) -> boolshould take in anActionnamedmove, and perform the action only if it is aSHOOTaction, and if the droid has remaining shots. You should take the other droid’s location by accessingother.location, and test if the other droid is shot. ReturnTrueif the other droid is shot,Falseif not, or the action is not performed. You should decrease the droids number of shots by one if the action is performed, regardless of the shot is successful.
>>> r2 = R2Droid(4, 4, (0, 0), 5)
>>> q5 = R2Droid(4, 4, (0, 3), 5)
>>> r2.shoot(q5, Action.SHOOT)
True
>>> r2.shots
4
>>> r2 = R2Droid(4, 4, (0, 0), 5)
>>> q5 = R2Droid(4, 4, (1, 2), 5)
>>> q5.shoot(r2, Action.SHOOT)
False
>>> q5.shots
4
- [5 points]
available_actions(self) -> Set[Action]returns a set of available actions the droid can perform given the current state of the droid and the rules defined above
>>> droid = R2Droid(4, 4, (1, 1), 5)
>>> droid.available_actions()
{<Action.MOVE_UP: 1>, <Action.MOVE_DOWN: 2>, <Action.MOVE_LEFT: 3>, <Action.MOVE_RIGHT: 4>, <Action.SHOOT: 5>}
>>> droid.move_location(Action.MOVE_UP)
>>> droid.available_actions()
{<Action.MOVE_DOWN: 2>, <Action.MOVE_LEFT: 3>, <Action.MOVE_RIGHT: 4>, <Action.SHOOT: 5>}
>>> droid = R2Droid(4, 4, (1, 1), 0)
>>> droid.available_actions()
{<Action.MOVE_UP: 1>, <Action.MOVE_DOWN: 2>, <Action.MOVE_LEFT: 3>, <Action.MOVE_RIGHT: 4>}
Note that you shouldn’t be assuming any other methods or fields for your agents in the later part to access, because we will be using our implementation when running your agents.
2. Implement Your Agents [55 points]
In this step, we will implement two types of agents, QAgent and MinimaxAgent. You will have to implement a basic Agent interface that looks like this:
class Agent(ABC):
def clear(self):
...
def get_best_move(self, self_droid: R2Droid, adv_droid: R2Droid, score_change: int) -> Action:
...
-
clear(self)should clear any information regarding to the current game. This will be called each time when a new game starts. Notice that you should not be clearing anything you agent learned about, e.g., don’t clear the Q-Table in your Q-Learning agent. -
get_best_move(self, self_droid: R2Droid, adv_droid: R2Droid, score_change: int, training: bool) -> Actionshould take in both droids and the score you gained from the action from the last round, and return the action that you want to perform at this round.score_changecan have values of -1, 0, and 1. For the first round,score_changewould be 0.trainingis meaningful for QAgent only, in case you want to tell whether we are training it or not (see more details below).
Note that you should be implementing the methods in the corresponding agents, not the Agent abstract base class.
For the following agents, you can assume that you are always dealing with a 4 by 4 game board as in the GUI.
QAgent [30 points]
Your QAgent should be using the reinforcement learning algorithm Q-Learning to learn from the games on-the-go. That is, you starts with a Q-Learning agent with a black Q-table, and for each action you do, the next time get_best_move is called, you should be updating your Q values based on the points you get and other factors.
You should be defining your own learning rate, discount factor, explore epsilon. Also, you have to define two very important things for your Q-Learning Agent:
-
[5 pts, manually graded] You are defining what is a state for your agent. Should you consider maybe the absolute location of your droid, or the relative distance from your droid and the opponent’s droid. You might also want to encode the number of shots the droid left, or the remaining rounds of the game into the state.
Notice that for each information you encode into your state, the size of the Q-Table increases exponentially, and the time it needs to train your agent also increases exponentially. But if you encode to little information into your state, it might not generalize well. Any reasonably sized state should get you full points.
-
[5 pts, manually graded] You also have to define your own reward function. A very naive reward function is just how much points your droid gets, but it can also be very complicated. For example, if you want to incentivize your droid to drive the other droid into the corner, then you can reward your droid more if it chooses to go to the corners. Any reasonably good reward function should get you full points.
Apart from implementing the required two interface methods, you should be (and definitely will have to) implement other helper methods relating to your Q-Learning algorithm. For example, a method that takes in the droid and the current state, and choose the best action based on the Q-values.
[20 points] Your droid will be given 3 minutes to train against our implementation of Q-Learning Agent (that is already being trained, and won’t learn while training with your agent). Then it will play another 100 games with our agent, from which the number of not-loosing games are the percentage of the total 20 points you get. For example, if after the training, in the 100 games that counts, you won for 80 games, drew for 8 games and lost for 12 games, then you get \(20 \times .88 = 17.6\) points.
You will be seeing your score in the autograder after you submit.
Minimax Agent (25 points)
Your MinimaxAgent should use the adversarial search tree and the Minimax algorithm to search for the optimal action to take for your droid. You should be defining your own depth to search for, as well as if you want to also implement alpha-beta pruning.
Notice that this game is different from your normal Minimax games, in a way that two sides move simultaneously. There are two ways you can mitigate this, one is the optimistic assumption, one is the pessimistic assumption. The optimistic way is to assume that your opponent moves first, such that you can “predict” what the opponent move will be. The pessimistic way is to assume that you move first, and your opponent can “predict” what your move will be. Both ways have its pros and cons, and can have consequences on the decisions your algorithms make. You can decide to implement either assumptions, or to try out both ways and use one of them, or combine the result from both assumptions using some methods.
[5 pts, manually graded] You should be defining your own evaluation function when the depth has reached or the game has ended. This can be quite similar to the reward function of the Q-Learning Agent, or it can be totally different. Any reasonably good evaluation function should get you full points.
[20 points] Your droid will play with our pre-trained Q-Learning Agent for 5 minutes or 100 games, whichever comes first, and a minimum of 20 games must be played (otherwise you get 0 points). You should tune your search depth to be reasonable so that it won’t take too long for each round (you can also make it adaptive by having a timer). The games you won worth 1, and the games you drawn worth .5, that over the total games played is the percentage of the total 20 points you get. For example, if you finished 100 games in 5 minutes, you won for 80 games, drew for 8 games and lost for 12 games, then you get \(20 \times (80 + 8 \times .5 ) /100 = 16.8\) points.
You will be seeing your score in the autograder after you submit.
Using GUI
You can start the GUI by executing
python3 r2d2_hw3.py [R2 Agent] [Q5 Agent] [Train Episodes]
Where you can set each agent to be either QAgent or MinimaxAgent. And you can set Train Episodes to be a number so that the agents will train for that many number of rounds (not number of games) before the GUI pops up.
For example, if you want to have two Q-Learning Agent train with each other for 100,000 episodes, you can have
python3 r2d2_hw3.py QAgent QAgent 100000
Or if you want to train the Q-Learning Agent with a Minimax Agent for 100,000 episodes, you can have
python3 r2d2_hw3.py QAgent MinimaxAgent 100000
After the GUI has popped up, you can see how two droids play against each other by pressing the spacebar to go to the next episode (round). A new round will be automatically restarted once a game has ended.
We also provided a Agent called KeyboardAgent, where you can have fun playing against computers. You can replace the R2Agent with KeyboardAgent, for example, if you want to play against your MinimaxAgent, you can run GUI with
python3 r2d2_hw3.py KeyboardAgent MinimaxAgent
If you want to play against your QAgent, you might want to train it first. You can have
python3 r2d2_hw3.py KeyboardAgent QAgent 100000 MinimaxAgent
Meaning you first train the QAgent with a MinimaxAgent for 100,000 episodes, and then when the GUI pops up you can play against it with your keyboard.
To use KeyboardAgent, use WASD to move up, left, down, and right respectively, and use space to shoot.